|
Yang Li I'm a researcher at Tencent (Hunyuan3D). I finished my Ph.D. with Tatsuya Harada at The University of Tokyo. During my Ph.D., I did an internship at Technical University Munich with Matthias Nießner, and an internship with Bo Zheng at Huawei Japan Research Center. I did a master in bioinformatics with Tetsuo Shibuya at The University of Tokyo. My research interests lie in the intersection of 3D computer vision, artificial intelligence, particularly focusing on registration, 3D/4D reconstruction, 3D Generative modeling, with applications in VR/AR, robotics, etc. |

|
Research Highlights† denotes project lead. |

|
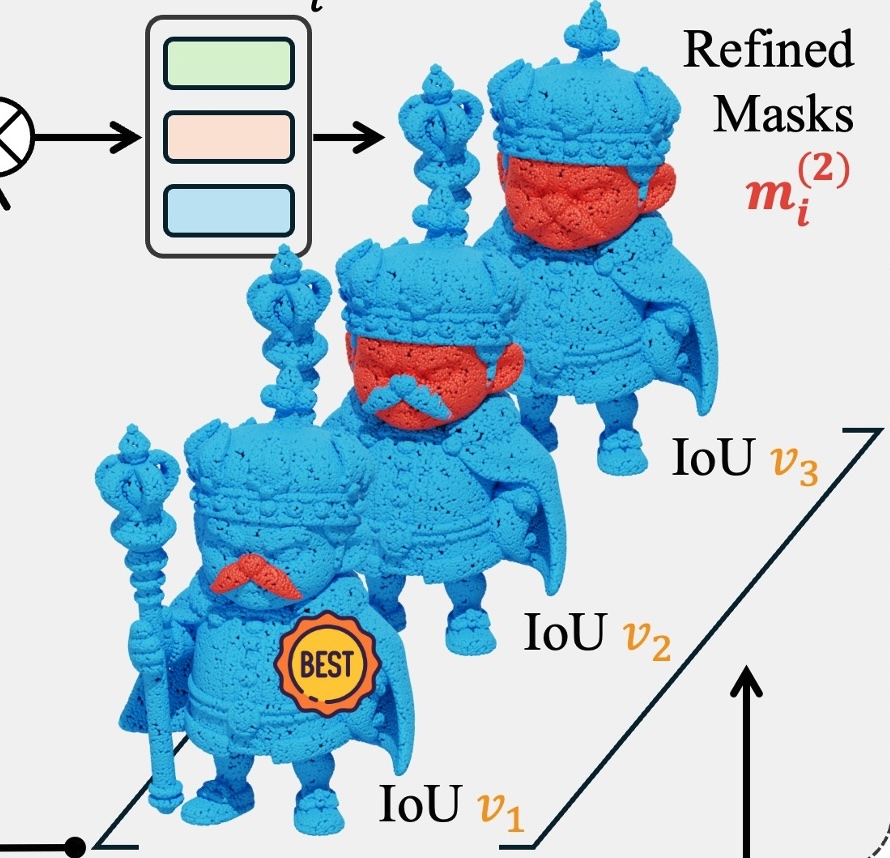
Xinhao Yan, Jiachen Xu, Yang Li†, Changfeng Ma, Yunhan Yang, Chunshi Wang, Zibo Zhao, Zeqiang Lai, Yunfei Zhao, Zhuo Chen, Chunchao Guo Arxiv preprint 2025 (Available on Hunyuan3D studio) Paper| Code We introduce X-Part, a controllable generative model designed to decompose a holistic 3D object into semantically meaningful and structurally coherent parts with high geometric fidelity. |
|
Changfeng Ma, Yang Li†, Xinhao Yan, Jiachen Xu, Yunhan Yang, Chunshi Wang, Zibo Zhao, Yanwen Guo, Zhuo Chen, Chunchao Guo Arxiv preprint 2025 (Available on Hunyuan3D studio) Paper| Code We propose a native 3D point-promptable part segmentation model termed P3-SAM, designed to fully automate the segmentation of any 3D objects into components. |

|
Yang Li, Victor Cheung, Xinhai Liu, Yuguang Chen, Zhongjin Luo, Biwen Lei, Haohan Weng, Zibo Zhao, Jingwei Huang, Zhuo Chen, Chunchao Guo Arxiv preprint 2025 (Available on Hunyuan3D studio) Project Page| Paper We introduce SeamGPT, an auto-regressive model that generates cutting seams by mimicking professional workflows. |

|
Zhongjin Luo, Yang Li †, Mingrui Zhang, Senbo Wang, Han Yan, Xibin Song, Taizhang Shang, Wei Mao, Hongdong Li, Xiaoguang Han, Pan Ji Arxiv preprint 2025 Project Page| Paper| video We present BAG, a Body-aligned Asset Generation method to output 3D wearable asset that can be automatically dressed on given 3D human bodies. |

|
Han Yan, Mingrui Zhang, Yang Li †, Chao Ma, Pan Ji Arxiv preprint 2024 Project Page| Paper| video PhyCAGE generates physically plausible compositional 3D assets from a single image. |

|
Yongzhi Xu, Yonhon Ng, Yifu Wang, Inkyu Sa, Yunfei Duan, Yang Li, Pan Ji, Hongdong Li Arxiv preprint 2024 Project Page| Paper| video This paper proposes a novel approach for automatically generating interactive (i.e., playable) 3D game scenes from users' casual prompts, including hand-drawn sketches and text descriptions. |

|
Han Yan, Yang Li †, Zhennan Wu, Shenzhou Chen, Weixuan Sun, Taizhang Shang, Weizhe Liu, Tian Chen, Xiaqiang Dai, Chao Ma, Hongdong Li, Pan Ji SIGGRAPH Asia 2024 Project Page| Paper| video| code We present Frankenstein, a diffusion-based framework that can generate semantic-compositional 3D scenes in a single pass. Unlike existing methods that output a single, unified 3D shape, Frankenstein simultaneously generates multiple separated shapes, each corresponding to a semantically meaningful part. |
|
|
Zhennan Wu, Yang Li † , Han Yan, Taizhang Shang, Weixuan Sun, Senbo Wang, Ruikai Cui, Weizhe Liu, Hiroyuki Sato, Hongdong Li, and Pan Ji Transaction on Graphics 2024 (Selected as SIGGRAPH 2024 Trailer Video) Project Page| Paper| video| Code We introduce the first 3D diffusion based approach for directly generating large unbounded 3D scene in both inddor and outdoor scenarios. At the core of this approach is a novel tri-plane diffusion and tri-plane extrapolation mechanism. |
|
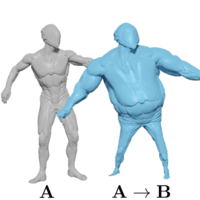
Yang Li and Tatsuya Harada NeurIPS 2022 paper| Code Neural Deformation Pyramid (NDP) break down non-rigid point cloud registration problem via hierarchical motion decomposition. NDP demonstrates advantage in both speed and registration accuracy. |
|
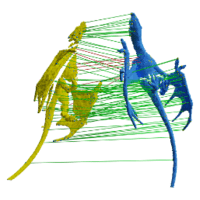
Yang Li and Tatsuya Harada CVPR 2022 (Oral Presentation) paper| video| Code We design Lepard, a novel partial point clouds matching method that exploits 3D positional knowledge. Lepard reaches SOTA on both rigid and deformable point cloud matching benchmarks. |

|
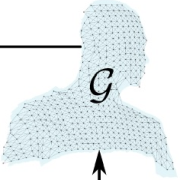
Yang Li, Hiraki Takehara, Takafumi Taketomi, Bo Zheng, and Matthias Nießner ICCV 2021 paper| video| Code We introduce 4DComplete, the first method that jointly recovers the shape and motion field from partial observations. We also provide a large-scale non-rigid 4D dataset for training and benchmaring. It consists of 1,972 animation sequences, and 122,365 frames. |
|
Yang Li, Aljaž Božič, Tianwei Zhang, Yanli Ji, Tatsuya Harada, and Matthias Nießner CVPR 2020 (Oral Presentation) paper | video We learn the tracking of non-rigid objects by differentiating through the underlying non-rigid solver. Specifically, we propose ConditionNet which learns to generate a problem-specific preconditioner using a large number of training samples from the Gauss-Newton update equation. The learned preconditioner increases PCG’s convergence speed by a significant margin. |
|
This website is based on source code. |